Gherbal v4: How a 200 MB Model Beat Giants at Language Identification
Language identification — determining what language a piece of text is written in — sounds like a solved problem. And for English, French, or Chinese, it basically is. But try asking a state-of-the-art model to tell apart Moroccan Arabic from Algerian Arabic, or to recognize Arabizi (Latin-script Darija) in a WhatsApp message, and you'll quickly discover how far we still have to go.
Today we're releasing the evaluation report for Gherbal v4, our language identification model that covers 214 languages — and outperforms models 6–8× its size. Both the full report and a one-pager summary are available for download on the Gherbal v4 page. Gherbal v4 is available for production use via the Sawalni API.
The Problem with Current LID Models
Most production language identification models share a common pattern: they're big, they're trained on web-crawled data, and they work great on the languages that dominate the internet. But the real world is messier:
- Arabic isn't one language. There are 16+ distinct Arabic dialects, from Moroccan Darija to Gulf Arabic to Hassaniya. Most LID models collapse all of them into "Arabic" — or worse, misidentify them entirely.
- Arabizi is invisible. Millions of North Africans write Arabic using Latin characters (3=ع, 7=ح, 9=ق). Not a single competing model we tested can identify it. Zero percent accuracy across the board.
- Low-resource languages get left behind. Languages like Kituba, Dyula, and Kamba have minimal web presence. Most models effectively don't know they exist.
- Efficiency matters. When you need LID at the edge — mobile devices, content moderation pipelines, real-time translation routing — performance and efficiency are critical.
The Evaluation
We ran the most comprehensive LID evaluation we're aware of: 17 models across 8 benchmarks spanning clean Wikipedia text, noisy web crawls, Arabic dialect social media, and African languages. The models range from legacy baselines to state-of-the-art multi-gigabyte architectures. The benchmarks include FLORES-200, MADAR, Atlasia-LID, CommonLID, WiLI-2018, Bouquet, and our own Gherbal-Multi test set. We evaluate under 5 scoping regimes to fairly compare models regardless of their native language count.
For the full methodology and per-language breakdowns, see the evaluation report.
The Results
At the V4 scope (214 languages), Gherbal v4 achieves the highest average accuracy:
| Model | Efficiency | Avg Accuracy |
|---|---|---|
| Gherbal v4 | High | 0.836 |
| OpenLID v2 | Standard | 0.824 |
| GlotLID | Heavy | 0.803 |
| NLLB-LID | Heavy | 0.711 |
Gherbal v4 outperforms models that are significantly larger. The secret isn't just architecture — it's data quality.
Version Evolution
The chart below shows how each Gherbal generation improved across all 8 benchmarks — from v1 through v4:
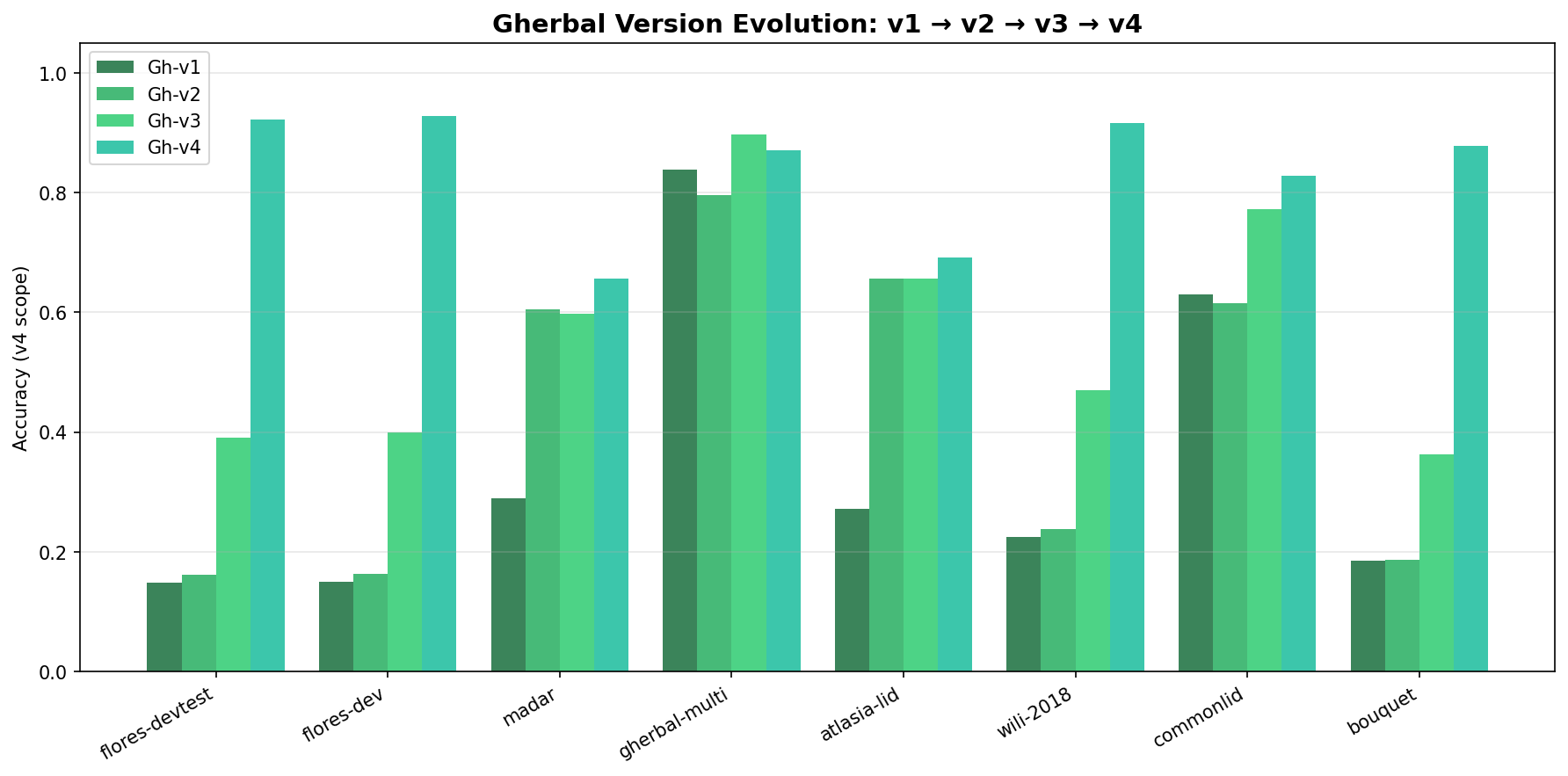
Every benchmark shows consistent, monotonic improvement. The biggest jumps came from v2→v3 (improved cleaning pipeline) and v3→v4 (advanced resampling and expanded training scope).
Data Quality > Data Quantity
Gherbal v4 is trained on less than 3 GB of data. OpenLID uses 21 GB. GlotLID uses 45 GB. Yet Gherbal achieves higher average accuracy.
The key is our 4-pass cleaning pipeline:
- Script validation — ensuring text actually matches its claimed language's writing system (you'd be surprised how much "Arabic" training data is actually English with Arabic labels).
- Cross-language deduplication — removing identical texts that appear under multiple language labels.
- Self-prediction disambiguation — training an internal model to flag confident disagreements with existing labels, finding the mislabeled needles in the haystack.
- Temperature resampling ($p^{0.3}$) — smoothing the distribution so tail languages get enough representation without hard-capping high-resource languages.
The result: smaller but cleaner training data produces a smaller but more accurate model.
The Arabic Dialect Gap
The most striking finding in our evaluation is the Arabic dialect coverage gap.
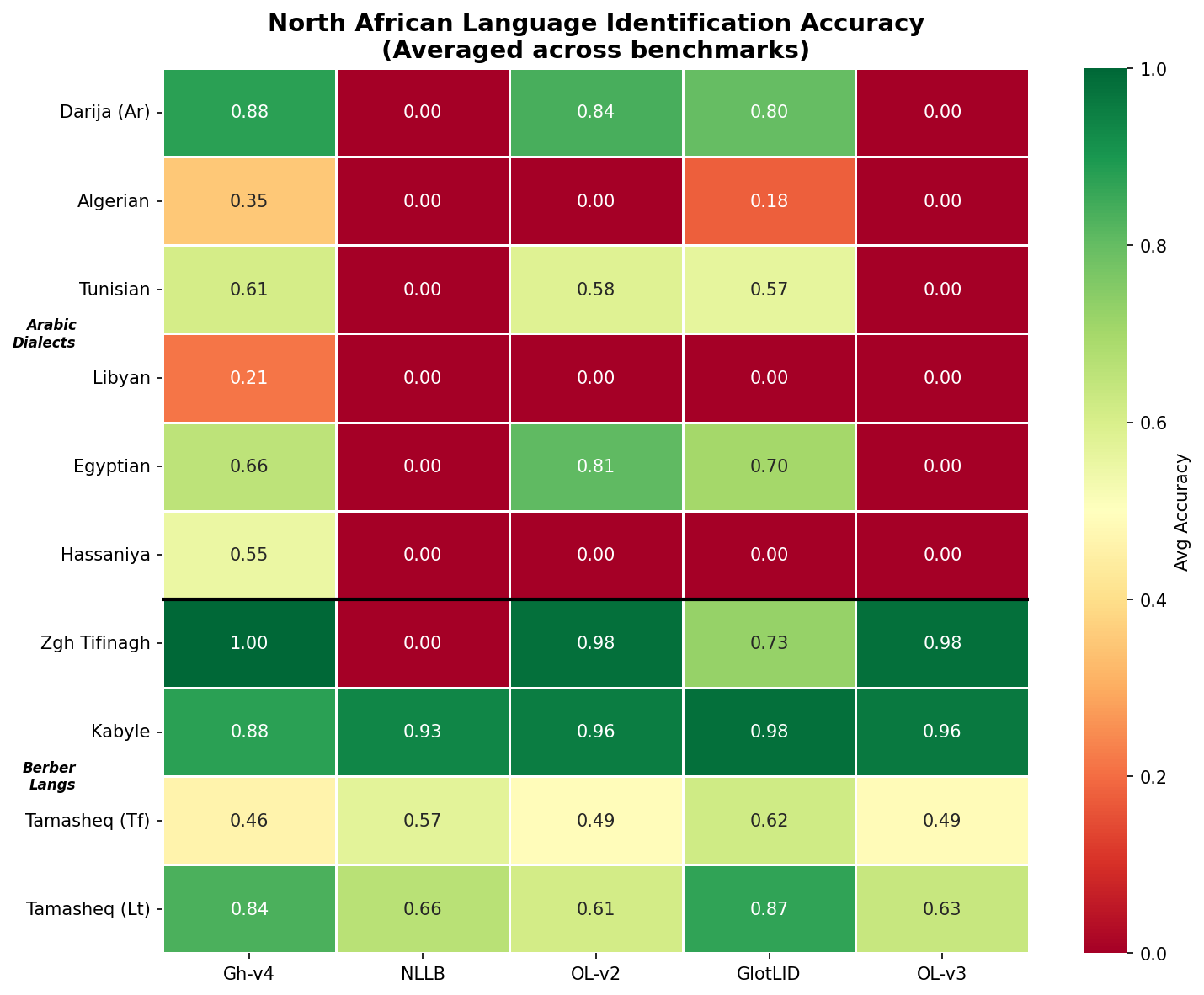
Gherbal v4 can identify all 16 Arabic dialect variants we tested. The next best model (OpenLID v2) covers 8. NLLB-LID — Meta's own model, trained on one of the largest multilingual datasets — scores 0.000 on every Arabic dialect except MSA.
On the MADAR benchmark (13 Arabic dialects), Gherbal v4 is the only model that even attempts to identify Gulf Arabic, Sudanese Arabic, Omani Arabic, or Yemeni Arabic. On Atlasia-LID, it's the only model that identifies Hassaniya or Bahrani Arabic.
These aren't academic curiosities. Arabic dialect identification is critical for content moderation, social media analysis, and language-aware services serving the 400+ million Arabic speakers worldwide.
Arabizi: The Language No Model Sees
Perhaps the most surprising finding: Arabizi (Moroccan Arabic written in Latin script) is completely invisible to every competing model.
Arabizi is the dominant written form for millions of young Moroccans on social media and messaging apps. Text like "Salam, ki dayra? Bghit nmchi l casa f weekend" is Moroccan Arabic written with Latin characters and French loanwords. It's a real, widespread way that people actually communicate.
Every Gherbal generation — from v1 to v4 — identifies Arabizi with 96–98% accuracy. Every competing model scores exactly 0%. Most confuse it with Maltese (the closest Latin-script language, since Maltese descends from Siculo-Arabic), or default to English/German/French.
For any application involving North African social media — content moderation, sentiment analysis, market research — Gherbal is currently the only LID option that won't completely misclassify the text.
African Language Coverage
Sub-Saharan Africa is another area where Gherbal v4 shines. On West and Central African languages, we're best-in-class:
| Language | Gherbal v4 | NLLB-LID | GlotLID |
|---|---|---|---|
| Kituba | 0.992 | 0.011 | 0.000 |
| Dyula | 0.703 | 0.026 | 0.029 |
| Kamba | 0.990 | 0.612 | — |
| Twi | 0.997 | 0.557 | — |
These aren't marginal improvements — they're the difference between a model that works and one that doesn't.
The Efficiency Story
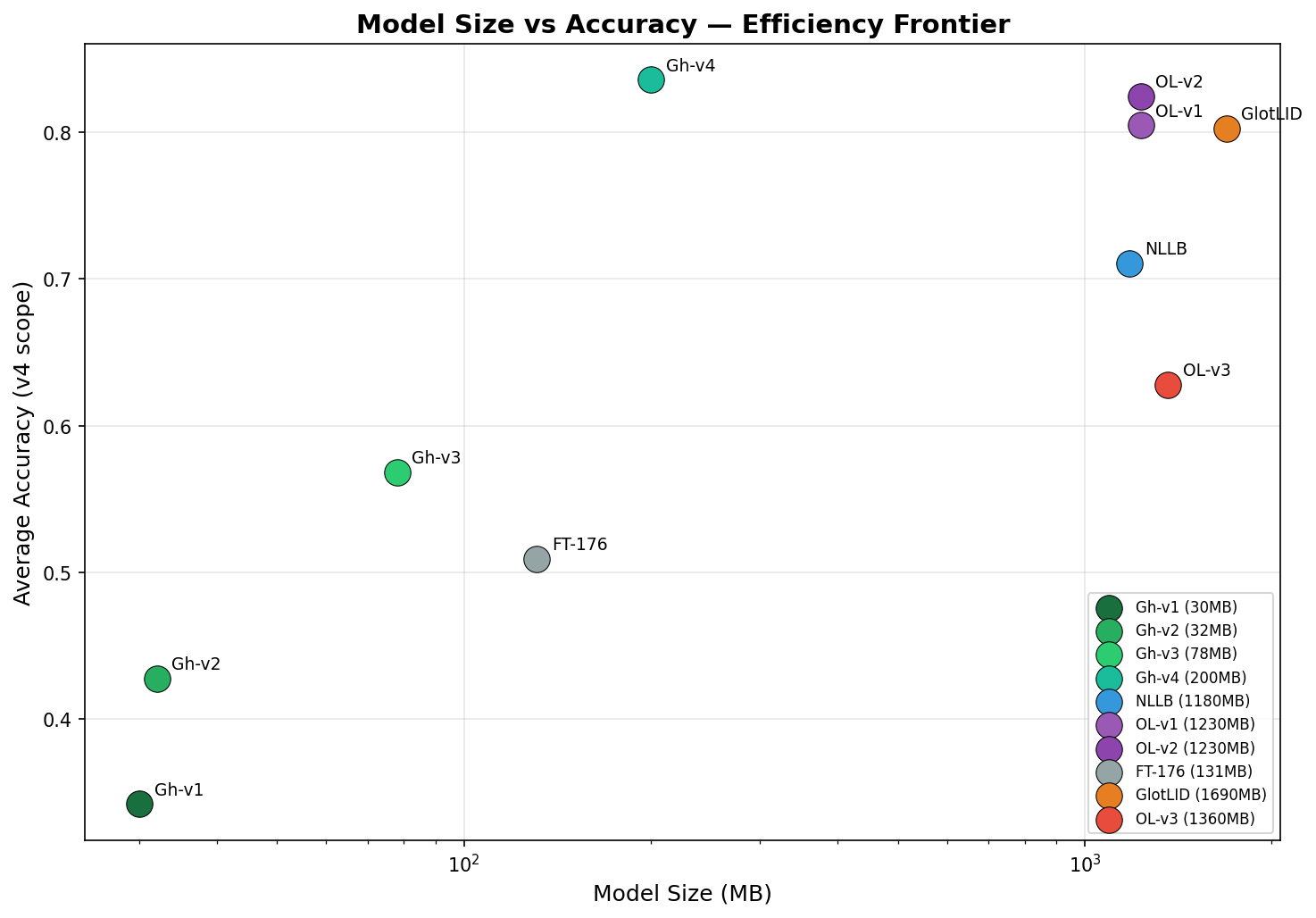
The efficiency numbers bear repeating. Gherbal v4 achieves 0.836 average accuracy at 200 MB. The next best model (OpenLID v2, 0.824) requires 1,230 MB. GlotLID (0.803) requires 1,690 MB. That's a 6.2× better accuracy-per-megabyte ratio.
For deployment scenarios where model size matters — mobile apps, edge devices, serverless functions, browser-based tools — this is the difference between feasible and infeasible.
Access via Sawalni API
Gherbal v4 is available for production use through the Sawalni API platform, alongside our other models like Madmon (multilingual embeddings). The API provides simple REST endpoints for language identification, making it easy to integrate Gherbal into any application or pipeline.
What's Next
We're continuing to expand coverage and improve accuracy:
- More languages — particularly Southeast Asian and South American indigenous languages
- Improved accuracy on the hardest Arabic dialects (Gulf, Omani, Yemeni)
- Transformer-based architectures for cases where FastText's n-gram features aren't sufficient
- Specialized models for short-text and code-switched scenarios
Language identification is the invisible infrastructure of multilingual NLP. When it works, nobody notices. When it fails, everything downstream breaks. Gherbal v4 is our contribution to making it work for languages that have been left behind.
Resources: